November 21, 2019
Unit 1 - Introduction to Statistics
Notes from MITx 18.6501x Fundamentals of Statistics covering probability, statistics, LLN, CLT, and fundamental inequalities
Article Notes
Published
November 21, 2019
Reading Time
7 minutes
Format
Mathematical notebook entry with static MathJax rendering.
This is my notes of the course “MITx: 18.6501x Fundamentals of Statistics” on edX. The session that I participated started on Sept 2, 2019. The purpose of this document is to help me remember what I have learnt.
Here is the MITx 18.6501x course page.
Note: a site to calculate/look up statistic curves/values: Keisan Online Calculator
Probability and Statistics
Very explicit explanation of the relation of probability and statistics:
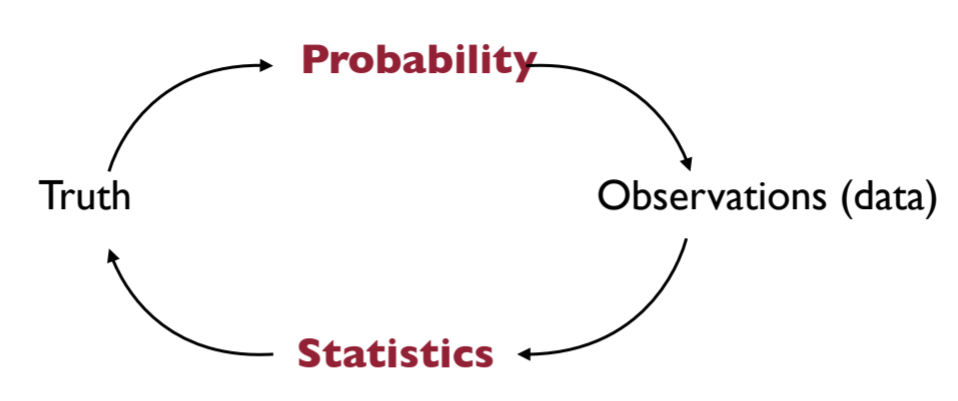
If we know the truth, then we can use “Probability” to predict/explain the “Observations”. However,
statistics is reverse engineering probability.
We have some observations (most of time we call them data), but we have no idea about the truth. We use the observations to estimate the truth. This is the purpose of statistics. From data, we try to recover what the truth is like.
Some conceptions
i.i.d.
Data that i.i.d. stands for independent and identically distributed .
A collection of random variables
- each
follows a distribution , all those distributions are the same, and are (mutually) independent
Sample average
We denote the sample average, or sample mean, of n random variables
Laws of Large Numbers (LLN)
Let
Laws (weak and strong) of large numbers (LLN):
where the convergence is in probability (as denoted by P on the convergence arrow) and almost surely (as denoted by a.s. on the arrow) for the weak and strong laws respectively.
When n is large enough, the sample average will converge to the expectation of variables.
Central Limit Theorem (CLT)
where the convergence is in distribution, as denoted by (d) on top of the convergence arrow.
Rule of thumb: n
When n is large enough, the sample average converges to a Gaussian distribution.
Three inequalities
Hoeffding’s Inequality
When n is not large enough to apply CTL, we can use Hoeffding’s Inequality.
Given n (n>0) i.i.d. random variables
Unlike for the central limit theorem, here the sample size n does not need to be large.
Markov inequality
For a random variable
Note that the Markov inequality is restricted to non-negative random variables.
Chebyshev inequality
For a random variable X with (finite) mean
When Markov inequality is applied to
Gaussian distribution
It is named after German Mathematician Carl Friedrich Gauss (1777–1855) in the context of the method of least squares (regression).
Gaussian density (PDF)
There is no closed form for their cumulative distribution function (CDF).
Useful properties of Gaussian
Invariant under affine transformation
Standardization
a.k.a. Normalization/Z-score. If
Useful to compute probabilities from CDF of
Symmetry
if
Quantiles
Let
Let
- if
is invertible, then - if
, then
Some important quantiles of the
| 2.5% | 5% | 10% | |
|---|---|---|---|
| 1.96 | 1.65 | 1.28 |
Three types of convergence
is a sequence of random variables - T is a random variable (T may be deterministic)
Almost surely (a.s.) convergence
is also known as convergence with probability 1 (w.p.1) and strong convergence.
Convergence in probability
Convergence in distribution
is also known as convergence in law and weak convergence .
for all continuous and bounded function
When n is large enough, they have the same distribution (the same PDF/CDF).
Properties
-
If
converges a.s., then it also converges in probability, and the two limits are equal a.s. -
If
converges in probability, then it also converges in distribution -
Convergence in distribution implies convergence of probabilities if the limit has a density (e.g. Gaussian):
-
Addition, Multiplication, and Division preserves convergence almost surely (a.s.) and in probability (
) More precisely, assume
Then,
- if in addition,
a.s., then
In general, these rules do not apply to convergence in distribution (d).
Slutsky’s Theorem
For convergence in distribution, the Slutsky’s Theorem will be our main tool.
Let
where
- if in addition,
a.s., then
Continuous Mapping Theorem
If